En los últimos años, muchas bases de datos con estructura Columnar han
tomado gran importancia en el mercado.
No cabe duda que las bases de datos con estructura Columnar funcionan
muy bien para ambientes de Inteligencia de Negocios. Bases de datos tradicionales como Oracle o
SQL Server han sabido competir muy bien en dicho mercado, sin embargo, se ha
comprobado que los formatos tradicionales (almacenamiento por fila) funcionan
muy bien para bases de datos transaccionales y bases de datos columnares tienen
su mayor rendimiento en bases de datos de explotación.
Oracle toma conciencia sobre esta disyuntiva y decidió combinar lo
mejor de ambos mundos en un nueva funcionalidad para Oracle 12c, IN MEMORY
COLUMN.
IN MEMORY COLUMN
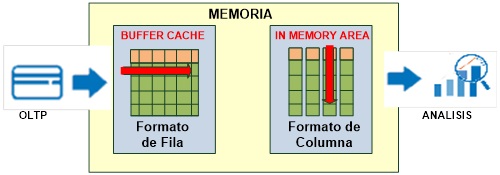
In Memory Column es una nueva opción de Oracle 12c que permite
almacenar en memoria los segmentos de base de datos de manera Columnar. Esta nueva funcionalidad no reemplaza el
formato tradicional de fila en el Buffer Cache debido a que la conversión a
columna se realiza en un nuevo Buffer llamado In Memory Area.

Como podemos observar en el grafico una tabla es enviada a memoria en
el formato de fila al Buffer Cache y en el formato de columna al IN MEMORY
AREA. El formato Columnar solo existe en memoria y no en disco. Debido a esta dualidad de formato , la activar
la funcionalidad In Memory Column es transparente para las aplicaciones.
Se observa también que a nivel
físico la estructura de datos sigue siendo la tradicional por lo que las tareas de backup y restore no se ven
afectadas.
Según la situación que se presente, el optimizador puede optar por utilizar
una tabla en formato de fila y en formato de Columna. Así tenemos que para operaciones DML (OLTP)
el optimizador utiliza el formato de fila y para sentencias SQL Analíticas, el
formato de columna.
¿Cómo configurar In
Memory Column?
Para poder configurar In Memory Column debemos de
seguir los siguientes pasos:
1. Verificar que el parámetro COMPATIBLE este definido con el valor
12.1.0.2 como mínimo.
SQL> show parameter compatible
NAME TYPE VALUE
------------------------------------
----------- ------------------------
compatible string 12.1.0.2.0
2. Definir el parámetro INMEMORY_SIZE que
define el tamaño del IN MEMORY AREA. Es importante definir un tamaño suficiente
para poder colocar todos los objetos que se requieren en formato de Columna.
SQL> alter system set inmemory_size=400M scope=spfile;
System altered.
3. Reiniciar la base de datos y
verificar si el nuevo segmento de memoria ha sido activado.
SQL> startup
ORACLE instance started.
Total System Global Area 1577058304 bytes
Fixed Size 2924832
bytes
Variable Size 402656992
bytes
Database Buffers 738197504 bytes
Redo Buffers 13848576
bytes
In-Memory
Area 419430400 bytes
Database mounted.
Database opened.
Una vez reiniciada la base de datos, el SGA estará compuesto de la
siguiente manera.

Es importante aclarar que el segmento de memoria IN MEMORY AREA ocupa
espacio del SGA y tiene un tamaño estático.
La consistencia de información entre el Buffer Cache y el IN MEMORY
AREA siempre se mantiene.
¿Cómo definir un segmento In Memory?
Una vez que definimos el Pool In Memory Area, se debe decidir que
segmentos subirán a memoria en este nuevo formato. Los segmentos pueden ser:
- Tabla
- Particiones
- Sub - Particiones
- Vistas Materializadas.
Para poder cargar segmentos a memoria Columnar debemos tener en cuenta
los siguientes aspectos:
1. DEFINICION
Definimos un objeto IN MEMORY cuando:
1.1 Creamos un segmento.
SQL> CREATE TABLE apps.cliente
( id number(10) NOT NULL,
nombre varchar2(50) NOT NULL,
ciudad varchar2(50),
CONSTRAINT cliente_pk PRIMARY KEY
(id)
) INMEMORY;
Table created.
1.2 Modificamos
un segmento ya creado.
SQL> ALTER TABLE apps.proveedor INMEMORY;
Table altered.
1.3 Creamos un segmento particionado.
SQL> create table apps.ventas
2
( anio number(4),
3
producto varchar2(10),
4
cantidad number(10,2)
5
)partition by range (anio)
6
( partition p1 values less than (2013) INMEMORY,
7
partition p2 values less than (2014),
8
partition p3 values less than (MAXVALUE) INMEMORY
9 );
Table created.
2. PRIORIDAD
Al momento de definir un objeto INMEMORY, podemos definir la prioridad de carga a la
memoria Columnar. Esto se realiza
especificando el atributo PRIORITY. Los
valores, ordenados desde la prioridad más alta, pueden ser:
-
CRITICAL
-
HIGH
-
MEDIUM
-
LOW
-
NONE
SQL> CREATE TABLE apps.departamento(
depart_id
number(10) NOT NULL,
depart_name varchar2(50) NOT NULL
) INMEMORY PRIORITY HIGH;
Table created.
SQL> ALTER TABLE apps.proveedor
INMEMORY PRIORITY LOW;
Table altered.
Cuando definimos una prioridad,
los objetos serán cargados a memoria Columnar cuando la base de datos inicia y
en el orden de prioridad.
Si no se define una prioridad, el objeto será cargado cuando sea
accedido por primera vez.
3. COMPRESIÓN
Es posible cargar los objetos a memoria Columnar de manera comprimida. Esto
nos ayuda maximizar el uso del IN MEMORY ARA.
Es posible modificar el tipo de compresión con el que se carga un objeto.
Por defecto los objetos cargan a memoria con una compresión moderada.
Tenemos los siguientes tipos de compresión ordenados por su capacidad de
comprimir.
-
NO
MEMCOMPRESS (Sin compression)
-
MEMCOMPRESS
FOR DML
-
MEMCOMPRESS
FOR QUERY LOW (compresión por
defecto)
-
MEMCOMPRESS
FOR QUERY HIGH
-
MEMCOMPRESS
FOR CAPACITY LOW | HIGH
SQL> ALTER TABLE apps.ventas INMEMORY MEMCOMPRESS FOR QUERY HIGH;
Table altered.
SQL> ALTER TABLE apps.cliente INMEMORY MEMCOMPRESS FOR CAPACITY HIGH;
Table altered.
Es importante recordar que a mayor compresión, mayor consumo de
recursos de CPU para poder acceder a la información de dichos objetos.
4. CONFIGURACION POR COLUMNAS
Es posible definir un grupo de columnas con una compresión
diferente.
Por ejemplo, de la tabla CLIENTE
(creada anteriormente) podemos definir diferentes tipos de compresión para
diferentes columnas.
SQL> alter table apps.cliente
INMEMORY
INMEMORY MEMCOMPRESS FOR QUERY LOW (ID)
INMEMORY MEMCOMPRESS FOR CAPACITY HIGH (NOMBRE)
NO INMEMORY
(ciudad);
Table altered.
5. MONITOREO
Para poder monitorear las tablas
que tienen definido la opción INMEMORY podemos consultar la vista DBA_TABLES o USER_TABLES. Existen nuevas
columnas que indican la configuración INMEMORY.
-
INMEMORY
-
INMEMORY_PRIORITY
-
INMEMORY_COMPRESSION
-
INMEMORY_DISTRIBUTE
-
INMEMORY_DUPLICATE
Los campos INMEMORY_DISTRIBUTE
e INMEMORY_DUPLICATE son efectivos para arquitecturas Real
Application Cluster.
SQL> SELECT owner, table_name, INMEMORY,
inmemory_compression, inmemory_priority "PRIORITY" from
dba_tables where inmemory_compression is
not null;
OWNER TABLE_NAME INMEMORY INMEMORY_COMPRESS PRIORITY
---------- -------------------- -------- ----------------- --------
APPS PROVEEDOR ENABLED FOR QUERY LOW LOW
APPS CLIENTE ENABLED FOR CAPACITY HIGH NONE
APPS DEPARTAMENTO ENABLED FOR QUERY LOW NONE
Para saber cuáles son las tablas que actualmente se encuentran en
memoria podemos consultar la vista V$ILM_SEGMENTS. En esta vista
podemos ver también que cantidad de bytes del total de las tablas se encuentran
cargadas en memoria Columnar.
SQL> SELECT SEGMENT_NAME, POPULATE_STATUS STATUS, BYTES, INMEMORY_SIZE,
BYTES_NOT_POPULATED NOT_POPULATED FROM v$im_segments;
SEGMENT_NAME STATUS BYTES INMEMORY_SIZE NOT_POPULATED
--------------------
--------- ---------- ------------- -------------
PROVEEDOR COMPLETED 327680 1179648 0
Una vez que se ha definido y cargado los objetos al IN MEMORY AREA, el
optimizador podrá optar por utilizar la información de manera Columnar o por
Filas.
In Memory Column en la Practica
Una vez configurado In Memory Column, procedemos
a poner en práctica la funcionalidad.
Para este ejemplo vamos a cargar 3 tablas a la memoria Columnar.
-
PROVEEDOR
-
ORDENCOMPRA
-
DIM_FECHA
SQL> ALTER TABLE apps.proveedor INMEMORY
PRIORITY LOW MEMCOMPRESS FOR QUERY LOW;
Table altered.
SQL> ALTER TABLE apps.ordencompra INMEMORY
PRIORITY NONE MEMCOMPRESS FOR QUERY HIGH;
Table altered.
SQL> ALTER TABLE apps.dim_fecha
INMEMORY
PRIORITY NONE MEMCOMPRESS FOR QUERY LOW;
Table altered.
Observamos que la unica tabla cargada en
memoria es la tabla PROVEEDOR debido a que tiene una prioridad de carga.
SQL> SELECT SEGMENT_NAME,
POPULATE_STATUS STATUS, BYTES, INMEMORY_SIZE, BYTES_NOT_POPULATED NOT_POPULATED
FROM v$im_segments;
SEGMENT_NAME STATUS BYTES INMEMORY_SIZE NOT_POPULATED
-------------------- --------- ---------- ------------- -------------
PROVEEDOR COMPLETED 327680 1179648 0
Procedemos a cargar las demás tablas.
SQL> select count(1) from apps.ordencompra;
COUNT(1)
----------
700000
SQL> select count(1) from
apps.dim_fecha;
COUNT(1)
----------
2556
SQL> SELECT SEGMENT_NAME, POPULATE_STATUS STATUS, BYTES, INMEMORY_SIZE,
BYTES_NOT_POPULATED NOT_POPULATED FROM v$im_segments;
SEGMENT_NAME STATUS BYTES INMEMORY_SIZE NOT_POPULATED
-------------------- --------- ---------- ------------- -------------
PROVEEDOR COMPLETED 327680 1179648 0
ORDENCOMPRA COMPLETED 83886080
24313856 0
DIM_FECHA COMPLETED 393216 1179648 0
Mediante el parámetro de sesión INMEMORY_QUERY
podemos habilitar o deshabilitar el uso de la memoria Columnar. De esa manera podemos observar el tiempo de
ejecución de una sentencia con y sin la funcionalidad.
Primero deshabilitamos la funcionalidad
INMEMORY. Luego ejecutamos sentencias
SQL y tomamos los tiempos de ejecución.
SQL> ALTER SESSION SET
INMEMORY_QUERY='DISABLE';
Session altered.
Sentencia SQL 1
SQL> SELECT lo_orderkey, lo_custkey, lo_revenue
2
FROM ORDENCOMPRA
3
WHERE lo_orderkey = 357;
LO_ORDERKEY LO_CUSTKEY LO_REVENUE
----------- ---------- ----------
357 12079
2825606
357 12079
6360563
357 12079
5690272
Elapsed: 00:00:01.35
Sentencia SQL 2
SQL> SELECT max(lo_ordtotalprice)
2
from ORDENCOMPRA;
MAX(LO_ORDTOTALPRICE)
---------------------
50450906
Elapsed: 00:00:01.31
Sentencia SQL 3
SQL> SELECT SUM(lo_extendedprice * lo_discount) INGRESOS
2
FROM ORDENCOMPRA o, DIM_FECHA d
3
WHERE o.lo_orderdate=d.d_datekey
4
and d.d_date='December 24, 1996';
INGRESOS
----------
5397325863
Elapsed:
00:00:01.38
Ahora activaremos la funcionalidad y
observaremos los tiempos de ejecucion de cada sentencia SQL.
SQL> ALTER SESSION SET
INMEMORY_QUERY='ENABLE';
Session altered.
Sentencia SQL 1
SQL> SELECT lo_orderkey, lo_custkey, lo_revenue
FROM ORDENCOMPRA
WHERE lo_orderkey = 357;
LO_ORDERKEY LO_CUSTKEY LO_REVENUE
----------- ---------- ----------
357 12079
2825606
357 12079
6360563
357 12079
5690272
Elapsed: 00:00:00.07
Sentencia SQL 2
SQL> SELECT max(lo_ordtotalprice)
from ORDENCOMPRA; 2
MAX(LO_ORDTOTALPRICE)
---------------------
50450906
Elapsed: 00:00:00.02
Sentencia SQL 3
SQL> SELECT SUM(lo_extendedprice * lo_discount) INGRESOS
FROM
ORDENCOMPRA o, DIM_FECHA d
WHERE o.lo_orderdate=d.d_datekey
and d.d_date='December 24, 1996';
INGRESOS
----------
5397325863
Elapsed: 00:00:00.06
Colocamos los tiempos de ejecución de
cada sentencia en un cuadro y vemos el
porcentaje de mejora.
Sentencia
|
NO INMEMORY (seg)
|
INMEMORY (Seg)
|
% Mejora
|
SQL 1
|
01.35
|
00.07
|
95%
|
SQL 2
|
01.31
|
00.02
|
98%
|
SQL 3
|
01.38
|
00.06
|
96%
|
Conclusiones.
Con los resultados podemos observar que
para muchas sentencias SQL, In Memory Column puede mejorar sus tiempos con solo
convertir las tablas grandes a formato Columnar.
Gracias a la funcionalidad IN Memory
Column podemos mejorar la performance de la base de datos con simples pasos. No es necesario configuraciones complejas en
la aplicación o tener experiencia amplia en performance tunning.
Espero les pueda servir.
No hay comentarios.:
Publicar un comentario